OCA_training_pathway
What is a Schema
You receive a data file from a colleague or you download the data from an instrument or database.
“What is this data?”. You see confusing column names. What are the units? What does this mean?
To help you understand and use the data you need a well documented data schema. A good schema will tell you what the column labels are and what they mean. It will tell you the units and it will tell you what type of data is in each column.
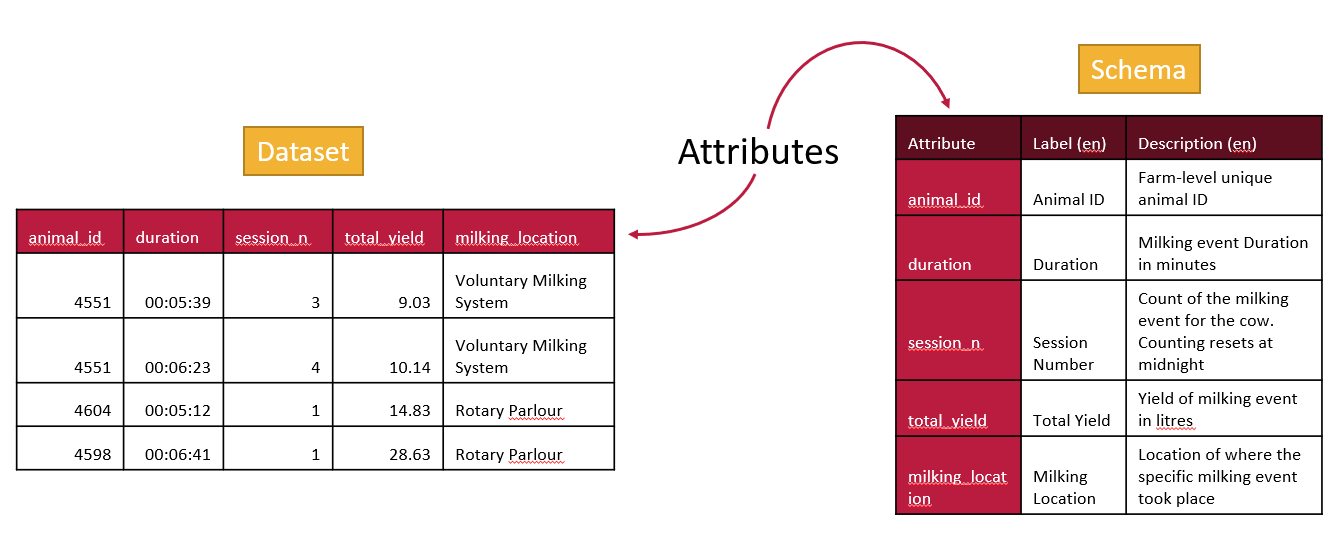
In short, a data schema represents a ‘blueprint’ of your data. All data follows some kind of data schema whether it is explicit or not. Good schemas are explicitly documented, better schemas document useful details, and really great schemas are prepared for the future and can be read and acted on by computers.
The better the schema and the more detail it contains, the more value the associated data has.
A schema can be thought of like an instruction manual that comes with your new TV. You probably briefly look at the manual to get started, and refer back to it when you get stuck. You probably store the manual with your other household manuals in a box or binder. Or if you don’t store it, you can search for it in an online repository using your TV model number (an identifier). The same for data schemas, they can be stored separately from the data, and even stored in separate repositories and referenced by many users through its identifier.
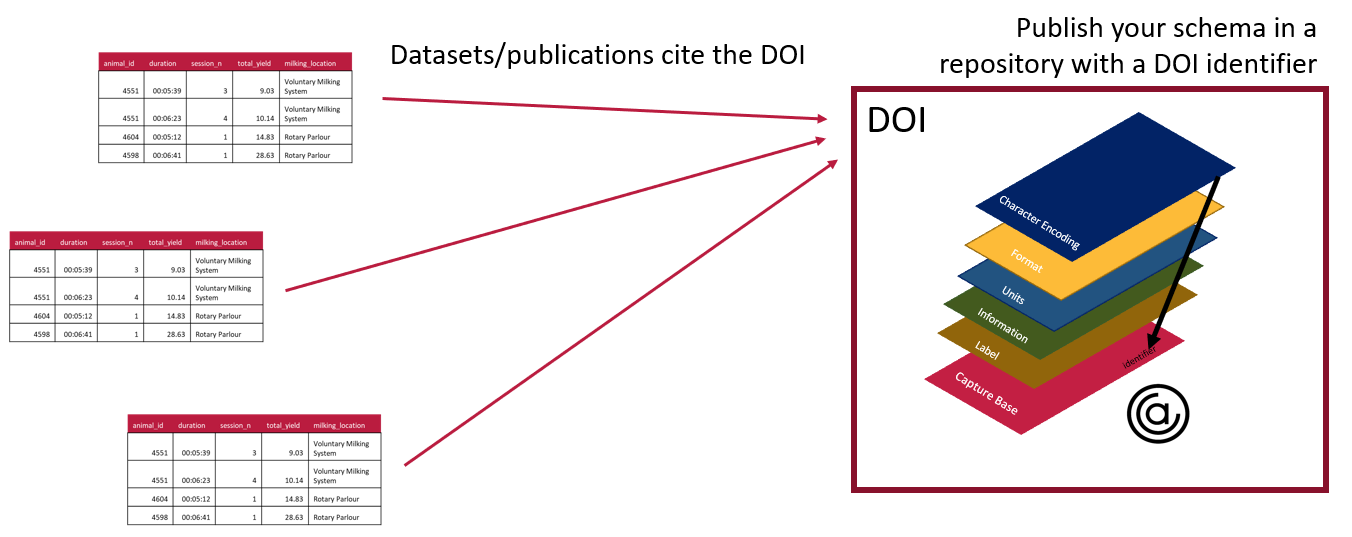
Really good schemas can be reused. They can be separated from the data and published as valuable research objects in their own right. You can publish a schema in a repository such as an institutional repository and give it a persistent identifier like a DOI that can be cited along with your datasets. In fact, sharing and using common schemas can save you a lot of work. If you are working on the same project, or if you are working with people in the same lab, you can benefit from sharing and reusing schemas.
By using an exisiting schema you can save yourself work in documenting your data. You can simply publish your data and point to the identifier (e.g. DOI) and version of the published schema. You can also work with the community and build more detailed schemas which will decrease the amount of work everyone needs to do in data documentation and also increase the value of everyone’s data. If a published schema isn’t suitable, you can take an existing one as a starting point and add the parts that you need.
At Agri-food Data Canada we are building tools to make it easy to write, share, extend, search, and use schemas. We are calling this work the Semantic Engine because we are helping researchers add more meaning to data.